|
Ozgur Kara I am a 4th year Computer Science PhD student at the University of Illinois Urbana-Champaign (UIUC), where I am advised by Founder Professor James M. Rehg. I have completed research internships at Adobe with Tobias Hinz in Summer 2024 (multi-shot video generation) and Google with Du Tran (generative video composition) in Summer 2025. My research focus is video generative AI. Some of my specific works include:
I am open to opportunities for collaboration and am always interested in discussing new research ideas. Please feel free to contact me via email. !!! Always looking for motivated students to work with — if you're interested in research on generative modeling, or want to come with your own proposal, feel free to reach out! 📃 Download my CV. Email / Google Scholar / Github / LinkedIn / Twitter / Travel Gallery |

Health Care Engineering Systems Center 1206 W Clark St. UIUC Urbana, IL, USA, 61801 |
News— scroll down for more ↓ |
|
|
|







Industry Experience |
||||||
|


Publications (* denotes equal contribution, † denotes corresponding author)
|
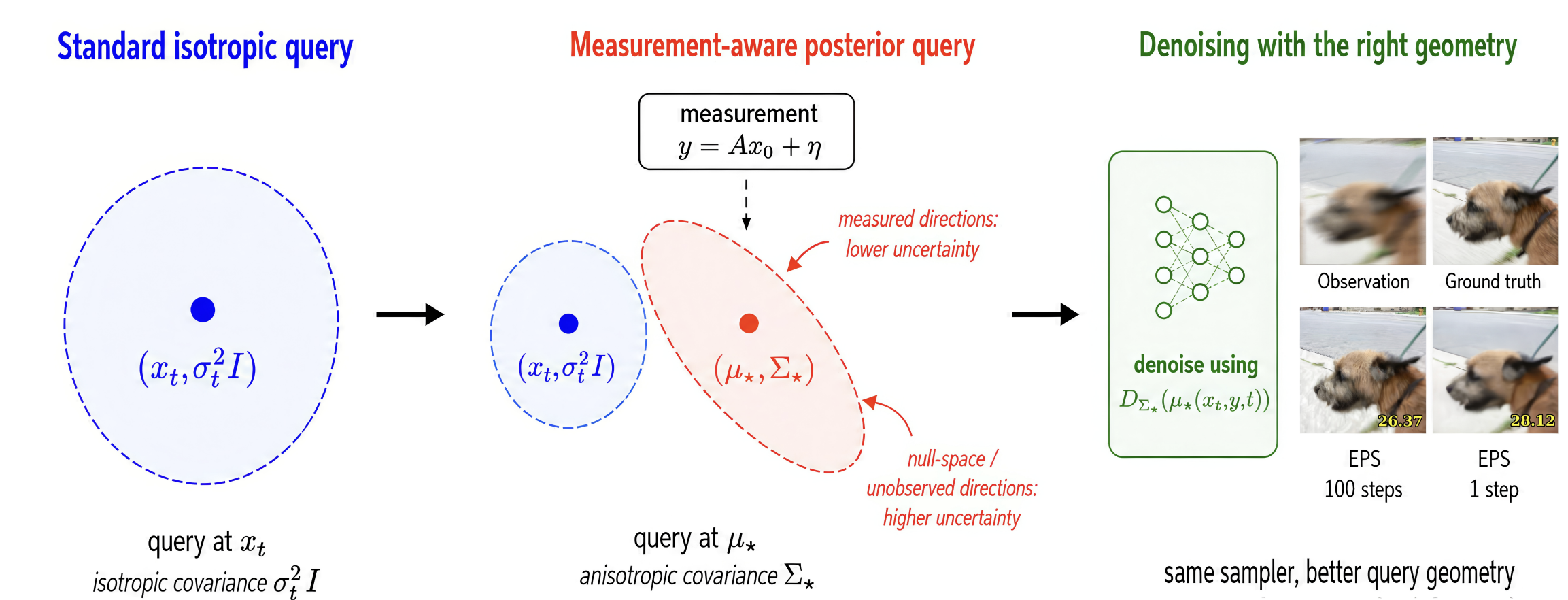
Exact Posterior Score Estimation for Solving Linear Inverse
Problems
Under Review, 2026 EPS solves linear inverse problems by replacing the standard isotropic query with a measurement-aware posterior query, leveraging anisotropic covariance to denoise with the right geometry and produce high-quality reconstructions in as few as a single step. Paper |
|
Layer-Aware Video Composition via Split-then-Merge
ECCV 2026 (European Conference on Computer Vision) Split-then-Merge (StM) is a new video composition framework that improves control and handles data scarcity by splitting unlabeled videos into foreground and background layers, and then self-composing them. Project Webpage / Paper Media: UIUC News / Official Google Channels in Instagram / Twitter |
|
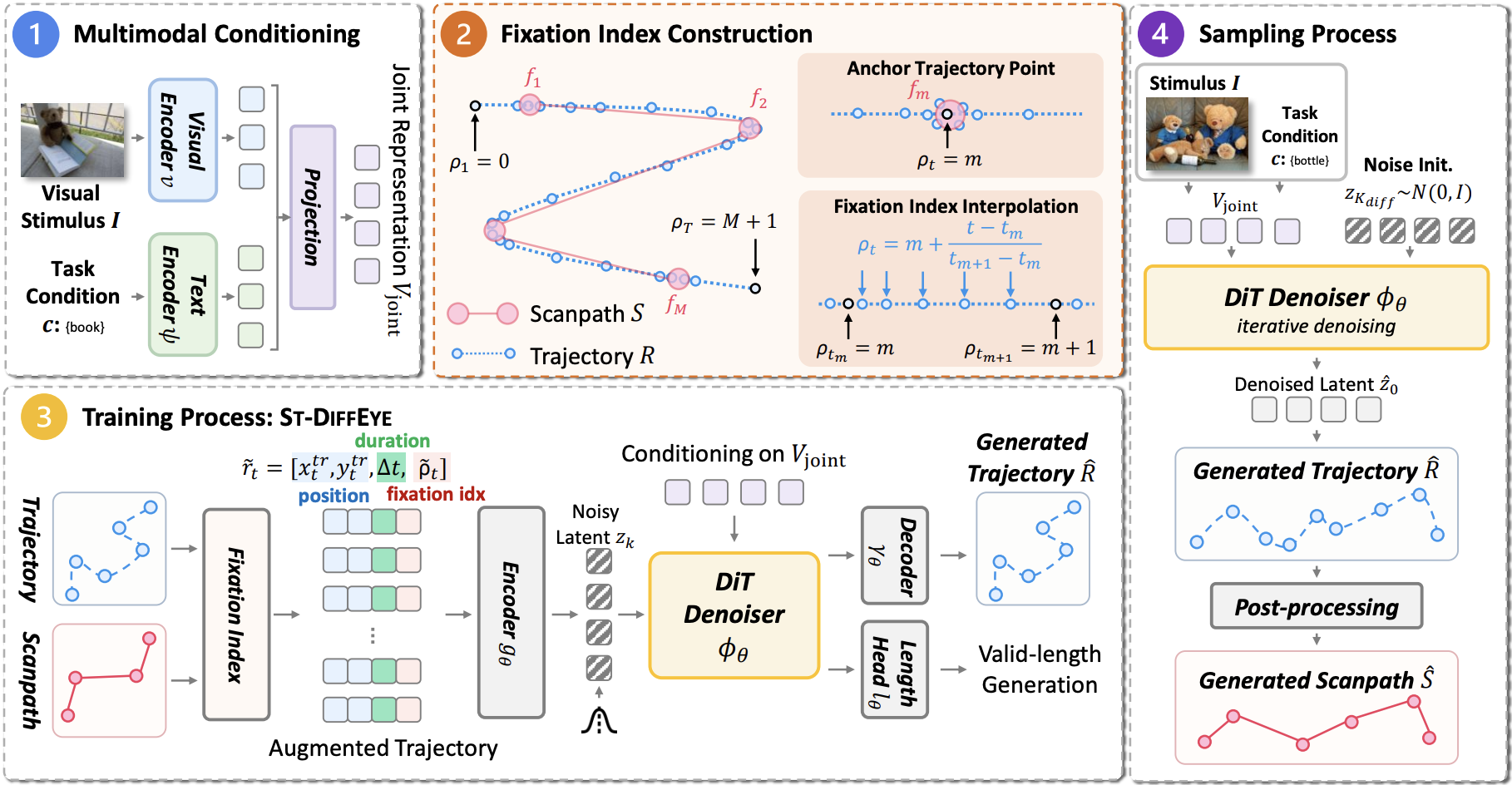
ST-DiffEye: Diffusion-Based Continuous Gaze Generation via Joint
Scanpath-Trajectory Modeling
Under Review, 2026 ST-DiffEye is a unified diffusion framework that jointly generates continuous gaze trajectories and discrete scanpaths by coupling both modalities as raw input channels, achieving state-of-the-art performance on task-driven visual search and free-viewing benchmarks. Project Webpage / Paper |

|
Immune2V: Image Immunization Against Dual-Stream Image-to-Video Generation
Under Review, 2026 Immune2V is an image immunization framework that protects images against unauthorized dual-stream image-to-video generation, preventing illicit video synthesis from protected content. Project Webpage / Paper / Code |
|
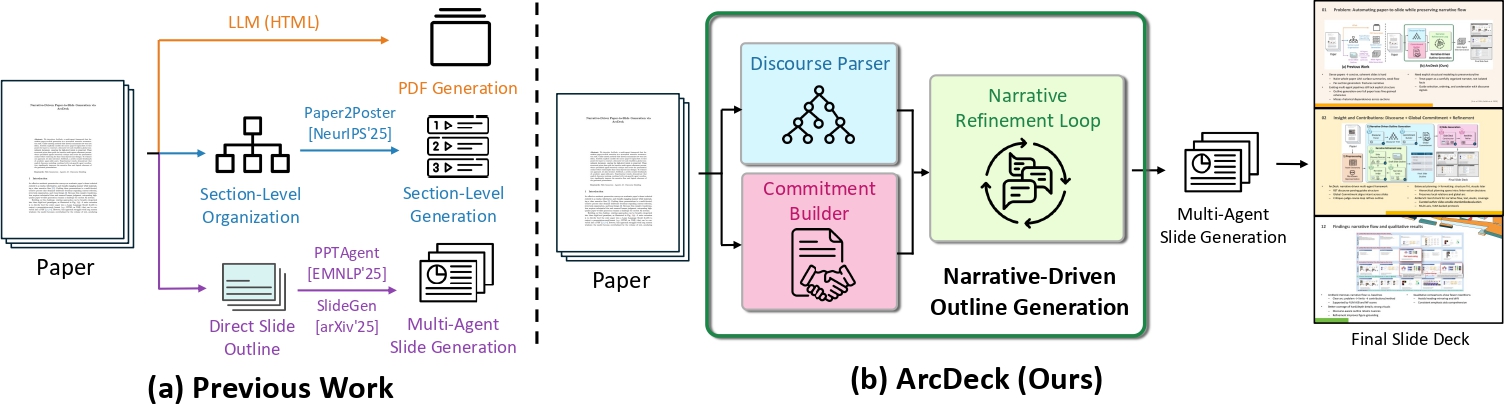
Narrative-Driven Paper-to-Slide Generation via ArcDeck
ECCV 2026 (European Conference on Computer Vision) ArcDeck is an agentic system for narrative-driven paper-to-slide generation that transforms academic papers into structured, visually coherent presentation slides. Project Webpage / Paper / Code |

|
DiffVax: Optimization-Free Image Immunization Against Diffusion-Based
Editing
ICLR 2026 (The Fourteenth International Conference on Learning Representations) DiffVax is an optimization-free image immunization framework that effectively protects against diffusion-based editing, generalizes to unseen content, is robust against counter-attacks, and shows promise in safeguarding video content. Project Webpage / Paper / Code (coming soon) |
|
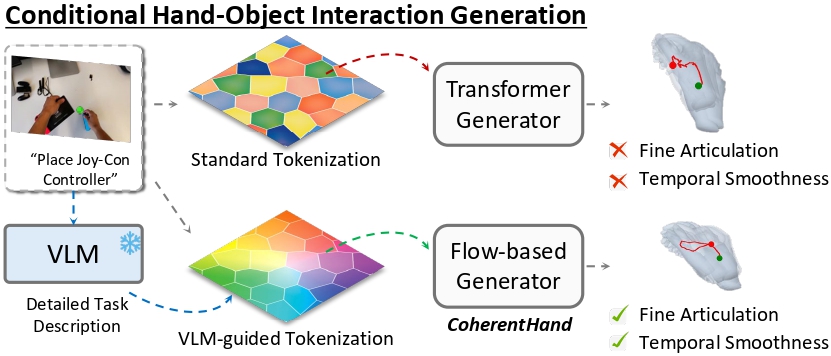
CoherentHand: Temporally Consistent 3D Hand Trajectory Synthesis with Semantic Motion Priors
CVPR Findings 2026 (IEEE/CVF Conference on Computer Vision and Pattern Recognition) CoherentHand synthesizes temporally consistent 3D hand trajectories using semantic motion priors, enabling realistic and coherent hand motion generation. Paper |
|
DiffEye: Diffusion-Based Continuous Eye-Tracking Data Generation
Conditioned on Natural Images
NeurIPS 2025 (The Thirty-ninth Annual Conference on Neural Information Processing Systems) We propose DiffEye, a diffusion-based generative model for creating realistic, raw eye-tracking trajectories conditioned on natural images, which outperforms existing methods on scanpath generation tasks. Project Webpage / Paper / Code |
|
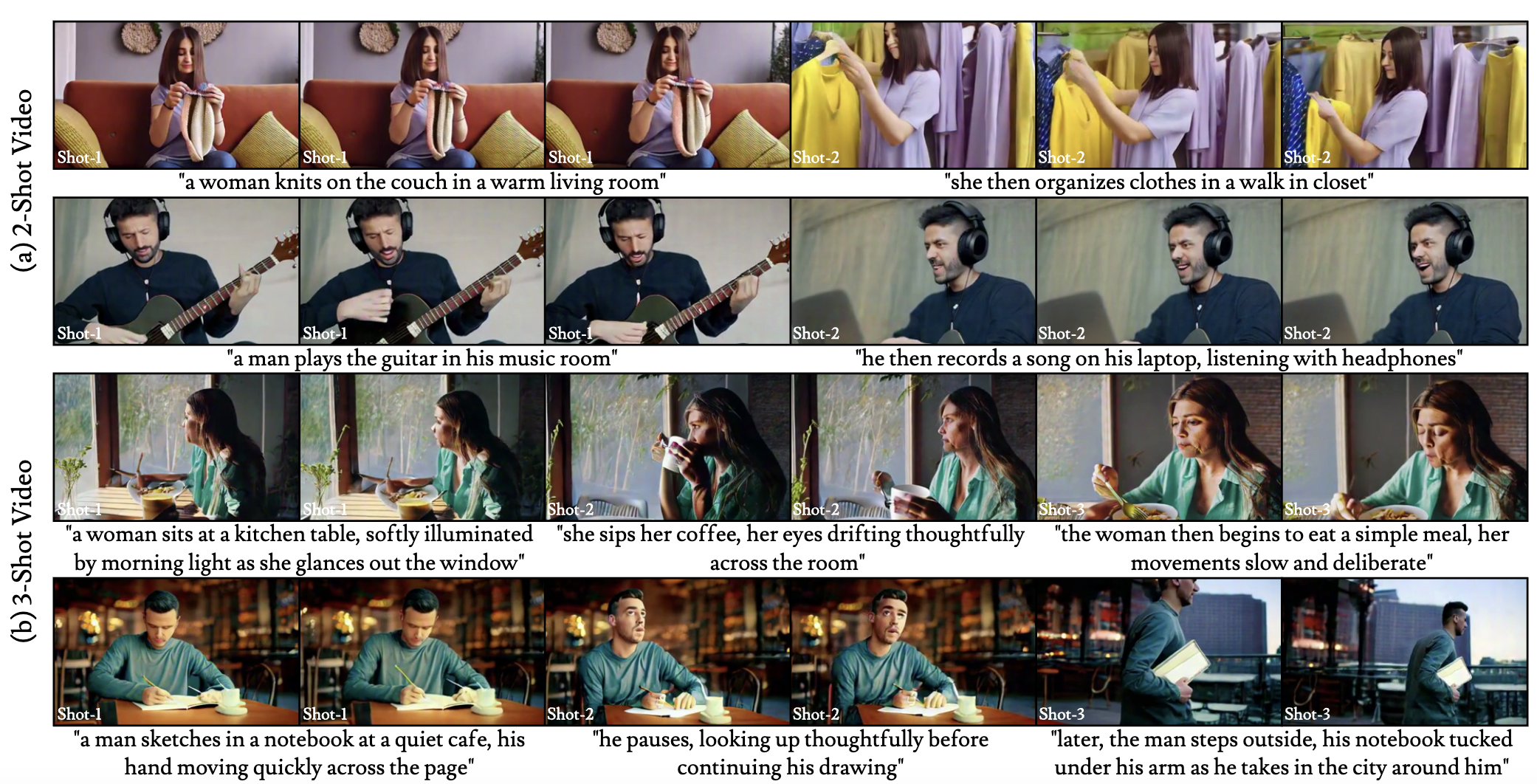
ShotAdapter: Text-to-Multi-Shot Video Generation with Diffusion
Models
CVPR 2025 (IEEE/CVF Conference on Computer Vision and Pattern Recognition) ShotAdapter enables text-to-multi-shot video generation with minimal fine-tuning, providing users control over shot number, duration, and content through shot-specific text prompts, along with a multi-shot video dataset collection pipeline. Project Webpage / Paper |

|
RAVE: Randomized Noise Shuffling for Fast and Consistent Video Editing with
Diffusion Models
CVPR 2024, Highlight (IEEE/CVF Conference on Computer Vision and Pattern Recognition) RAVE is a zero-shot, lightweight, and fast framework for text-guided video editing, supporting videos of any length utilizing text-to-image pretrained diffusion models. Project Webpage / Paper / Code / HuggingFace Demo / Video Media: Voxel51 Talk / NewGenAI / creativaier / JanRT / Future Thinker @Benji |
|
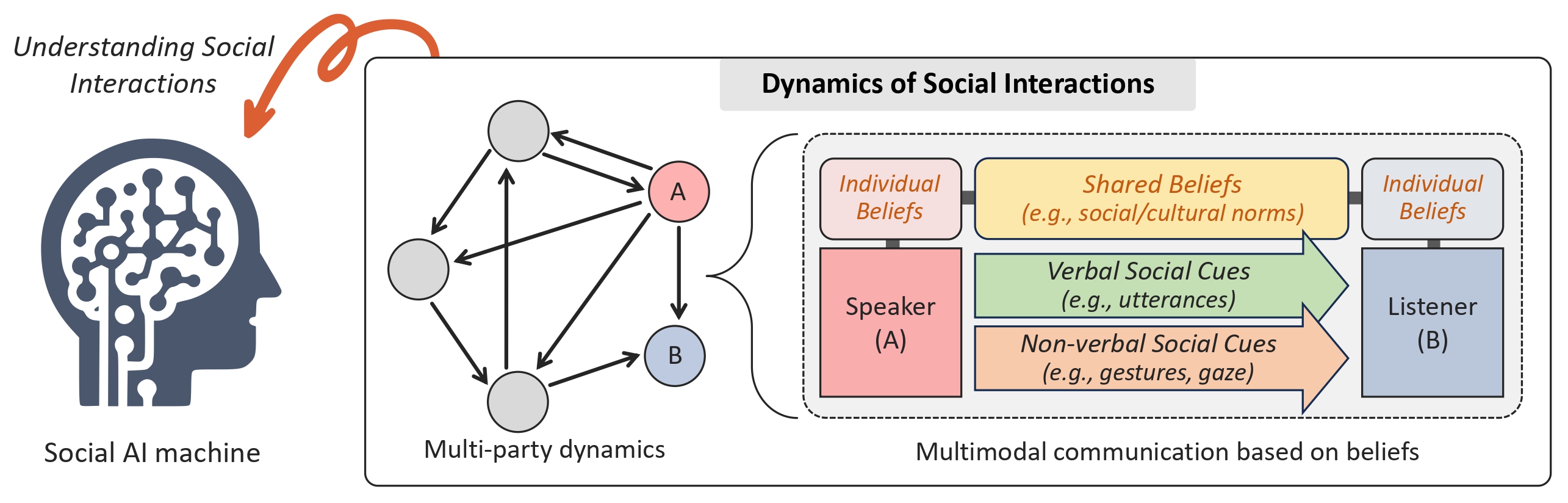
Towards Social AI: A Survey on Understanding Social Interactions
In Submission, 2025 This is the first survey to provide a comprehensive overview of machine learning studies on social understanding, encompassing both verbal and non-verbal approaches. Paper |
|
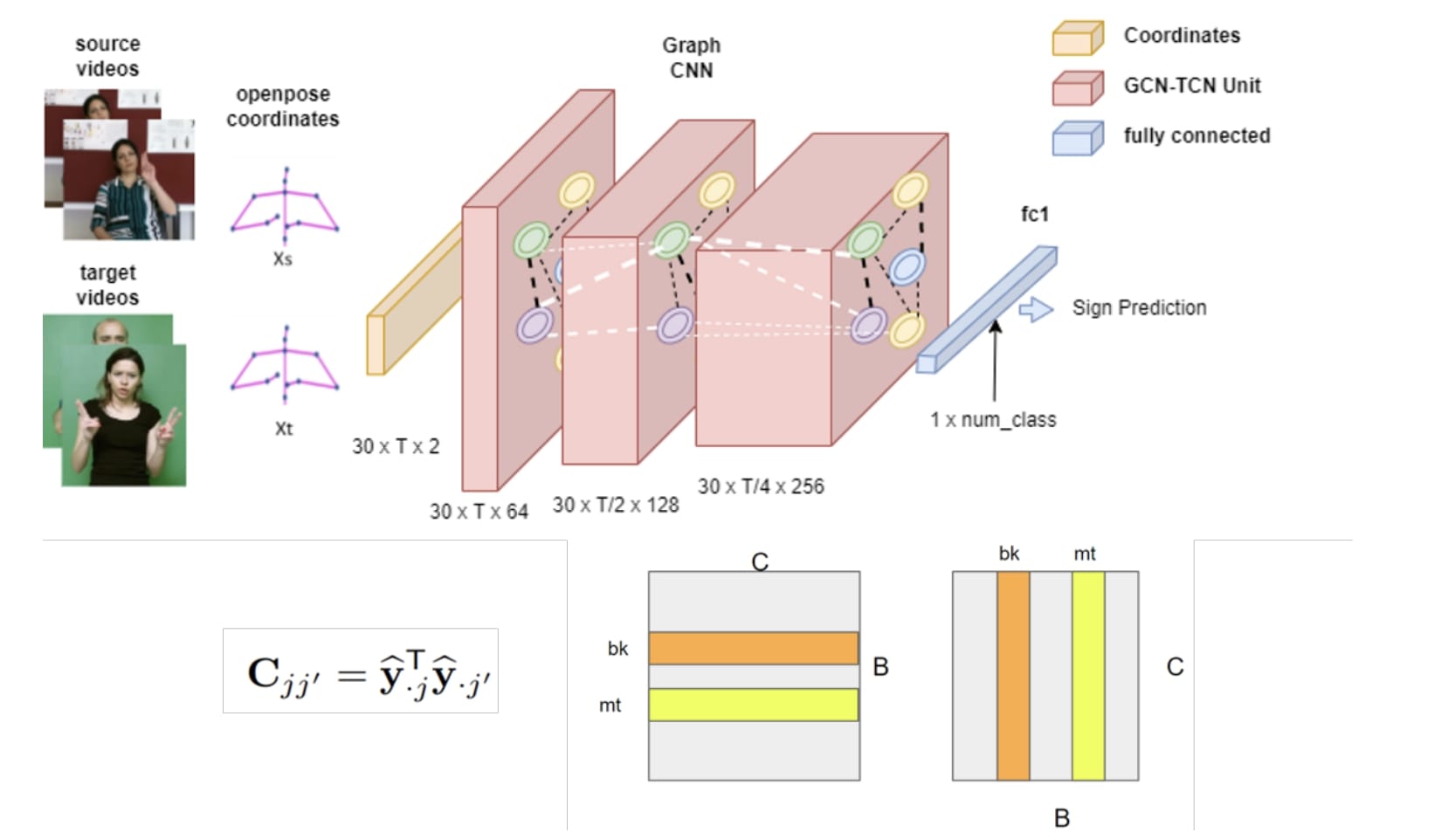
Transfer Learning for Cross-dataset Isolated Sign Language Recognition in
Under-Resourced Datasets
FG 2024 (IEEE International Conference on Automatic Face and Gesture Recognition) This study provides a publicly available cross-dataset transfer learning benchmark from two existing public Turkish SLR datasets. Paper / Code |
|
|
Leveraging Object Priors for Point Tracking
ECCV 2024 ILR Workshop, Oral (Instance-Level Recognition Workshop at European Conference on Computer Vision) We propose a novel objectness regularization approach that guides points to be aware of object priors by forcing them to stay inside the the boundaries of object instances. Paper / Code |
|
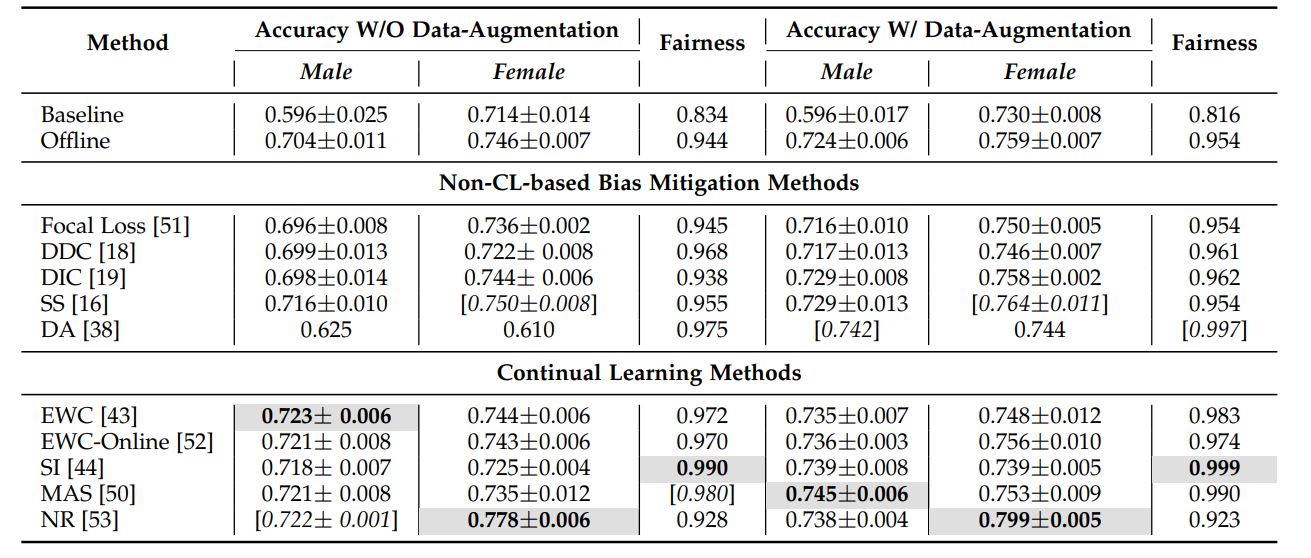
Domain-Incremental Continual Learning for Mitigating Bias in Facial
Expression and Action Unit Recognition
IEEE TAC 2022 (IEEE Transactions on Affective Computing) we propose the novel use of Continual Learning (CL), in particular, using Domain-Incremental Learning (Domain-IL) settings, as a potent bias mitigation method to enhance the fairness of Facial Expression Recognition (FER) systems. Paper / Code |
|
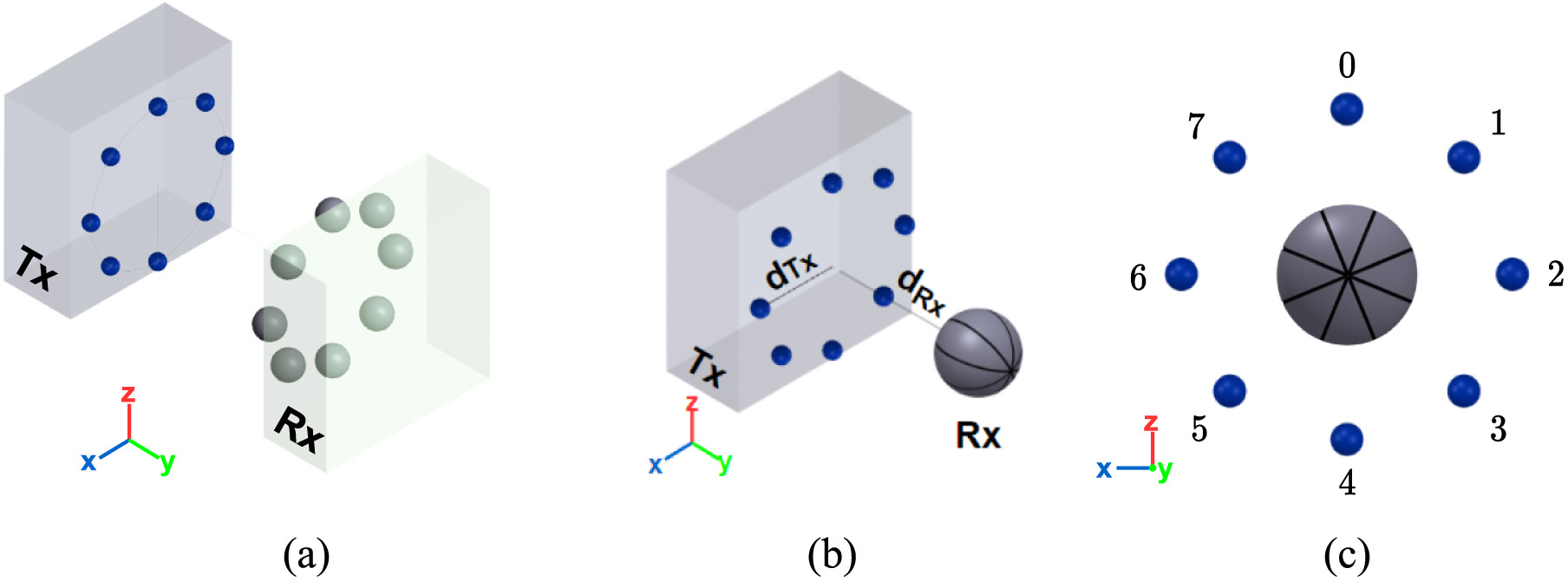
Molecular Index Modulation using Convolutional Neural Networks
Nano Communication Networks 2022 We propose a novel convolutional neural network-based architecture for a uniquely designed molecular multiple-input-single-output topology, aimed at mitigating the detrimental effects of molecular interference in nano molecular communication. Paper / Code |
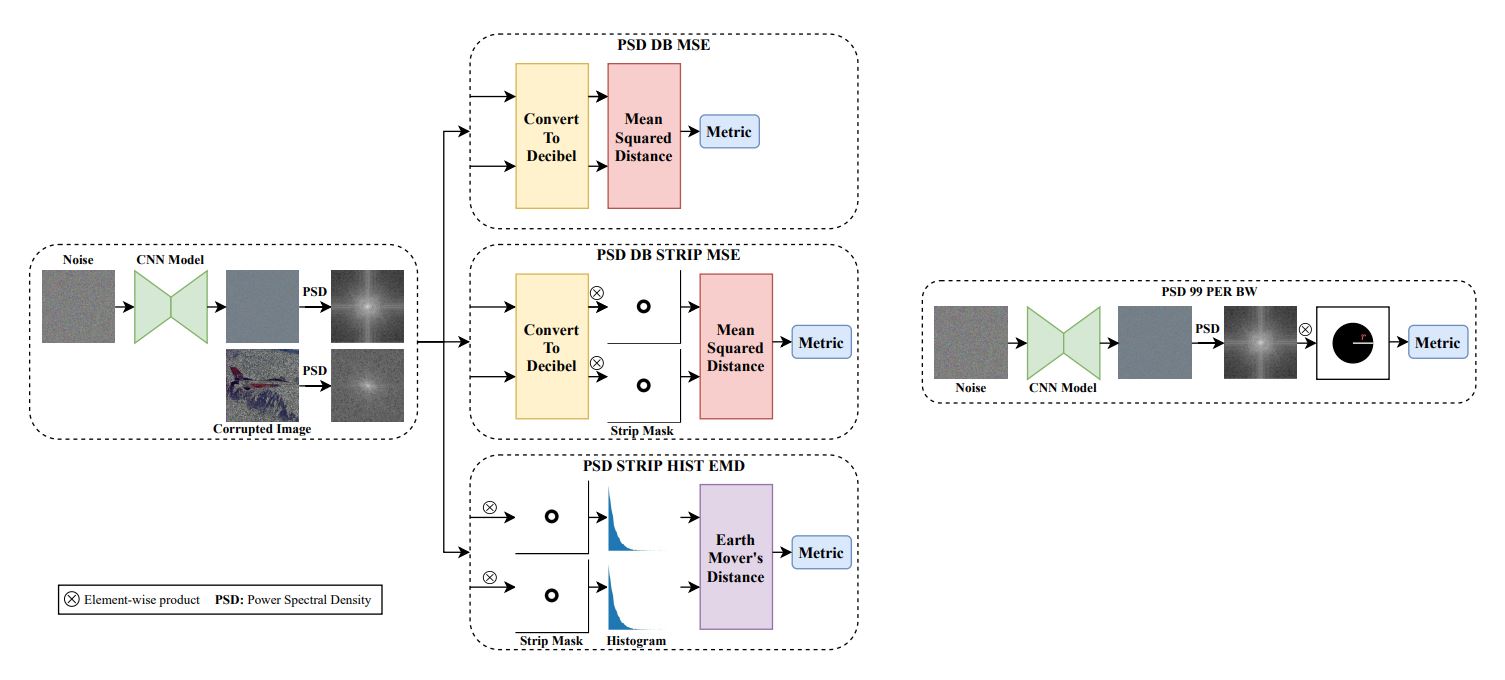
|
ISNAS-DIP: Image-Specific Neural Architecture Search for Deep Image
Prior
CVPR 2022 (IEEE/CVF Conference on Computer Vision and Pattern Recognition) ISNAS-DIP is an image-specific Neural Architecture Search (NAS) strategy designed for the Deep Image Prior (DIP) framework, offering significantly reduced training requirements compared to conventional NAS methods. Paper / Code / Video |
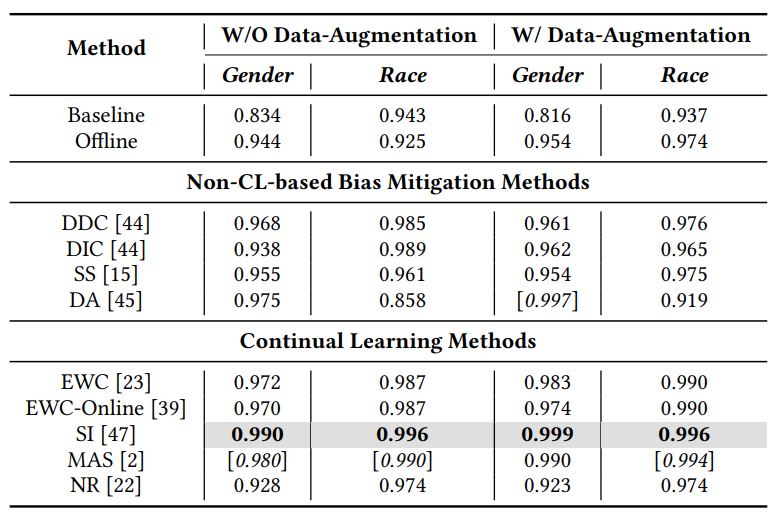
|
Towards Fair Affective Robotics: Continual Learning for Mitigating Bias in
Facial Expression and Action Unit Recognition
LEAP-HRI 2021 (Workshop on Lifelong Learning and Personalization in Long-Term Human-Robot Interaction) We propose the novel use of Continual Learning (CL) as a potent bias mitigation method to enhance the fairness of Facial Expression Recognition (FER) systems. Paper / Code |
|
Neuroweaver: a platform for designing intelligent closed-loop
neuromodulation systems
Brain Stimulation: Basic, Translational, and Clinical Research in Neuromodulation, Elsevier, 2021 Our interactive platform enables the design of neuromodulation pipelines through a visually intuitive and user-friendly interface. (Google Summer of Code 2021 project) Paper / Code |
Service & Recognition
Professional Service
- Workshop Organizer: AI for Visual Content Generation Editing and Understanding (CVEU) [Webpage]
- CVPR 2026 (Lead Organizer)
- SIGGRAPH 2025 (Co-organizer)
- CVPR 2025 (Lead Organizer)
- Outstanding Reviewer:
- ICCV 2025 (Top 2%)
- CVPR 2025 (Top 5%)
- ECCV 2024 (Top 10%)
- Program Committee / Reviewer:
- CVPR 2024, 2025, 2026
- ICCV 2025
- ECCV 2024
- NeurIPS 2023, 2025
- ICML 2024
- ICLR 2024, 2025
- AAAI 2025
- IEEE Transactions on Affective Computing
- ACM Transactions on Graphics
Invited Talks
- Voxel51 Computer Vision Meetup, Visual AI for Video Use Cases 2026
- Google Computer Vision Reading Group, ShotAdapter: Text-to-Multi-Shot Video Generation with Diffusion Models 2025
- UIUC Computer Vision Group Lunch, RAVE: Randomized Noise Shuffling for Fast and Consistent Video Editing with Diffusion Models 2024
- Voxel51 Computer Vision Meetup, GenAI for Video: Diffusion-Based Editing and Generation, [Recording] 2024
- More Than 101, Review of Basic Probability and Introduction to Diffusion Models 2023
Teaching
- CS444 Deep Learning for Computer Vision, UIUC 2026 Spring
- ECE2026 Introduction to Signal Processing, Georgia Institute of Technology 2022 Fall
Mentorship
- Amreen Tejani (UIUC, Chemistry (Pre-Med)) Spring 2026
DiffEye applications on medical imaging (as part of the Undergraduate Research Apprenticeship Program (URAP)). - Furkan Horoz (METU, BS CS) Fall 2025-Present
Multi-agentic slide generation (ArcDeck, ConvDeck).
Characterizing adversarial attacks on diffusion modeling. - Emir Kisa (Bogazici University, BS EE) Spring 2026-Present
Personalized video generation. - Zeqian (Richard) Long (UIUC, BS CS) Spring 2025 - Spring 2026
Adversarial attacks on video diffusion models (Immune2V). - Aditya Ved, Nalin Kundu (UIUC, BS CS) Spring 2025
Developed deepfake prevention mobile app (URSA, Awarded 1st Place in Research Symposium). - Miguel Aenlle (UIUC, BS CS) Fall 2024 - Fall 2025
Google Summer of Code (GSoC) 2025 Contributor. Real-time video editing mobile app (URSA). - Tarik Can Ozden (Bogazici University BS CS → UIUC MS CS) Spring 2024-Present
Immunization model against deepfake attacks (DiffVax, ICLR 2026).
Multi-agentic slide generation (ArcDeck, ConvDeck). - Peter Guan (UIUC, BS CS) Fall 2024
Real-time video editing mobile app (URSA). - Sarper Yurtseven (YTU BS Maths. → Polimi MS Comp. Maths.) Summer 2024
Google Summer of Code (GSoC) 2024 Contributor. Universal controller diffusion models. - Ioannis Valasakis (King's College London, PhD) Summer 2023
Google Summer of Code (GSoC) 2023 Contributor. - Mehul Sinha (Manipal University, B.Tech → MS CS @ USC) Summer 2022
Google Summer of Code (GSoC) 2022 Contributor.
Scholarships
- UIUC CS PhD Fellowship Addendum 2024-2026
- Georgia Tech ECE Departmental Fellowship 2022-2024
- Georgia Tech Otto F. and Jenny H. Krauss Fellowship 2022-2023
- Summer@EPFL Fully Funded Summer Internship Program 2022
- 2205 TUBITAK Undergraduate Scholarship Holder 2022
- Outstanding Success Scholarship Holder from Turkish Educational Foundation (TEV). 2019-2022
- 2247-C TUBITAK Research Internship Scholarship 2021-2022
Awards & Achievements
- Served as a mentor in the Google Summer of Code program in 2022, 2023, 2024, and 2025. 2025
- Recognized as an Outstanding Reviewer at ECCV, ranked among the top 10% of all reviewers. 2024
- Attended the 2023 International Computer Vision Summer School (ICVSS), ranked among the top 25% of 614 applicants (approximately 154 individuals), [Project] 2023
- Participated in the CIMPA Research School on Graph Structure and Complex Network Analysis. 2023
- Attended the highly competitive Summer@EPFL program, with a 2% acceptance rate. 2022
- Placed among the top 50 teams worldwide in the Google Developer’s Solution Challenge, selected from over 5,000 teams, [Project] 2022
- Placed 3rd in the Yildiz Bootcamp and was directly invited to the Yildiz Technopark Pre-Incubation Program. 2022
- Successfully completed Google Summer of Code with the project "Graphical User Interface for OpenAI Gym," selected among 1,205 students from 6,991 applicants (17% acceptance rate), [Project] 2021
- Placed 3rd out of 172 projects (top 1.7%) in the TUBITAK Undergraduate Research Project Competition. 2021
- Ranked among the top 10 teams regionwide in the Google Solution Challenge with the project titled "Torch in Darkness." 2020
- Placed 1st out of 100 projects (top 1%) in the TUBITAK Undergraduate Research Project Competition for the project "Joint Depth Estimation and Object Detection Software," [Project] 2020
- Placed 3rd out of 15 projects (top 20%) in the IEEE METU Pixery Hackathon with the project "Mobile Application for Blind People," [Project] 2020
- Finalist among 81 teams in the Turkish Airlines Travel Datathon. 2019
- Ranked 180th out of 2 million (top 0.009%) in the Turkish National University Entrance Exam. 2018
- Received the Republic Honour Award at Kadikoy Anadolu High School, awarded to one student out of 340 annually. 2018
- Placed 3rd nationwide in the TUBITAK High School Research Project Competition for the project "Drone for Landmine Detection Using GPS," [Project] 2018
- Placed 1st regionwide in the TUBITAK High School Research Project Competition for the project "An Autonomous Hexapod for Helping Search Teams After Earthquake," [Project] 2017
- Accepted into the CS Bridge program, a two-week programming course led by Stanford TAs. 2016
|
This website is adapted from this source code. |
